We're all used to streamed text content from LLM chat APIs. With the release of OpenAI's text-to-speech API we wanted to explore how to stream audio at the same time as text.
A lot of chat APIs use server-sent events. This works well for text based data and there are nice primitives to use in the browser to handle these event streams.
However we wanted to stream text and binary audio data at the same time. One option could have been to use base64 encoding, but this felt hacky and inefficient. It involves extra processing on both the server and the client.
With the help of GPT4 we discovered the multipart/x-mixed-replace content type. This used to be natively supported in browsers for streaming images, e.g. from webcams. Most browsers no longer support it directly for image/video data but you can still use fetch and handle the stream manually.
This is perfect for our use case as it means we can send different content types in a single stream. For GPT4 this can include text, images, audio and JSON.
This article is a walk through of implementing this in a NextJS app - full code here.
Demo
This is a quick demo of the code in action, with full duplex audio and multiple simultaneous tool (function) calls.
How it Works
It is actually simple. You define a boundary string and then separate each part of the stream with that boundary. Each part has a content type header followed by the data (in whatever format you want).


Streaming Text and Audio Together
We wanted to start playing audio as soon as text was being streamed back from the chat completions API (rather than wait for the full response). A quick implementation might send each chunk of text to the TTS API. However this would be inefficient and result in very unnnatural audio as often OpenAI will send a single word at a time. So we wrote a simple function that sends a minumum of 30 characters and only full sentences to the TTS API.
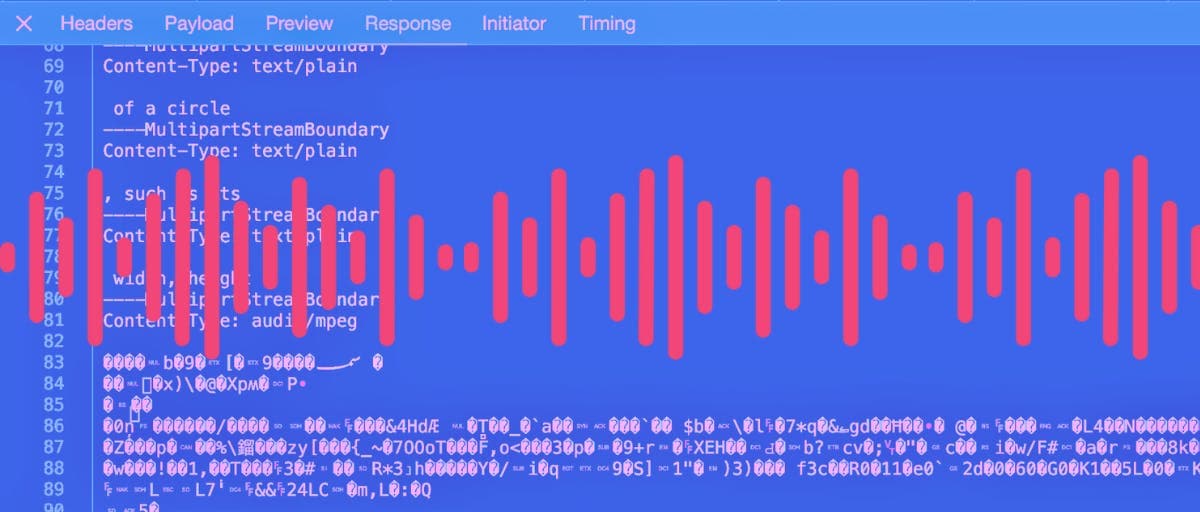
Each returned audio stream is then pushed to the client. The end result is a mixed stream that contains both text and audio data. Audio is sent a sentence at a time, while text is streamed a word at a time with new partitions every 5 words. The result is a stream that could look like this:
----MultipartStreamBoundary
Content-Type: text/plain
How can I help you
----MultipartStreamBoundary
Content-Type: text/plain
today?
----MultipartStreamBoundary
Content-Type: audio/mpeg
���� BINARY DATA ����
A longer response would have the text and audio interspersed and contain 100s of text and audio sections.
Sending the boundary string and content-type header after every 5 words of text isn't efficient. Seeing as we are in control of both the client and the server we could probably do something cleverer, however for a demo this works well enough.
Client-Side Processing
Each time the client receives a chunk of data it checks for the encoded boundary string. When it finds a boundary it processes the data buffered so far. It first checks for a content-type header, if it is text data it updates the messages array with the content, if its audio data it queues it up to play and if its JSON data it runs the associated functions.
Here is the (GPT4 generated and lightly edited) code to handle the stream, splitting it at each boundary string. Notice that because we're expecting binary and text data we keep the processing at the binary level rather than converting to text.
All the code for processing and handling this data is here.
The actual processing of each chunk of data then looks like this:
In the above code we are dealing with 4 different types of content in just a few lines of code. Compare this to the code that handles receiving function/tool responses in vercel's ai library.
Playing Audio in the Browser
Remarkably playing the audio in the browser doesn't take many lines of code.
We ended up with a fairly simple hook that implements an audio queue where each audio chunk is played sequentially. The end result sounds like a single audio stream.
Supporting Multiple Function Calls
The newer OpenAI models support calling multiple functions (now called tools) in a single response. Now that we have a way of sending text and audio from the server in a single stream it made sense to also send JSON. There is no point streaming the individual parts of a function argument in the way that they are received from OpenAI. So we decided to buffer up any tool responses and send them as an application/json chunk. This makes the client implementation simpler as it now only receives complete JSON. Arguably its semantically better as well - our stream can now send 3 different types of data each with their own content type.
This demo shows off the power of multiple tools by defining separate functions to change the styling of a circle, square and triangle. It is a lot more powerful being able to ask the LLM to do multiple things at the same time.
Future: Image Generation
Currently DALL-E isn't integrated into the chat completions API, but apparently thats coming soon. When it does there will be another content type we can add to our flexible multipart/x-mixed-replace stream 😊
Bonus: Audio Recording
After finding how easy playing audio is in modern browsers we decided to implement recording as well - complete with silence detection and waveform rendering.
The code needed for recording and sending to the server is super simple. Full code is here, but here is a simplified extract:
Conclusion
This was a fun experiment that we think could be useful for many projects. It seems highly likely that as a tech community we are going to be building a lot of software on top of LLM APIs. It also seems highly likely that more LLMs will become multi-modal AND that no matter the speed improvements there will be many use-cases where you want to stream the data to your application rather than wait for the full response.
Maybe its time for the return of multipart/x-mixed-replace!
ps we're regularly launching AI based features into smart data analysis platform - AddMaple